大规模预训练,接着进行下游任务微调现在已经成了各领域默认的范式,神经科学也未能例外。短短两三年间,很多面向fMRI的基座模型开始涌现,像是BrainLM、Brain-JEPA、NeuroSTORM,其训练方法是在海量数据上做自监督预训练,而后微调,用来刻画BWAS关系(脑龄、性别、疾病诊断、认知评分)等等,但是有一个疑问始终悬而未决,它们当真有用吗?这些以 MAE 或 predict-next-token 为训练核心的大模型,真能胜过FC(functional connectome)吗?毕竟,如今多数模型训练范式还是在重建,但是在 fMRI这种高噪声数据上做重建,我个人感觉模型大多学到的噪声。这可以用一个简单比较就可以体现出来。用基座模型的embedding和FC进行比较,如果基座模型的embedding在统一的下游任务上都打败不了FC,是不是现在基座模型目前的训练方式有问题呢?进一步什么样的训练方式能够克服FC的基线呢?是不是需要更优质的数据呢。下面我仅从个人看法进行一些说明。
我一直有一种说不清的感觉,把通用 foundation model 的那套范式直接搬到 fMRI 上,总觉得哪里不对。我认为是训练目标和我们关心的对象之间的错配,为什么这么说呢。一方面,MAE 或 predict next token 的本质都是去重建信号本身,而在 fMRI 这种低信噪比数据上,重建损失里相当大一部分其实来自噪声,模型很容易把算力花在拟合噪声上,这在EEG的大模型上很容易体现,他的噪声太多了,很难实现cross subject的泛化。Brain-jEPA 之所以转去 latent 空间做预测,某种意义上正是在回避这件事。另一方面,即便抛开噪声,自监督学到的多半是 within subject 的时序动态,而 BWAS 真正需要的是稳定的、trait-level 的个体差异,FC 恰恰是通过对整段时间求协方差,把瞬时状态平均掉、只留下个体间稳定的连接结构,这正好对齐了 BWAS 的目标。FC 不是一个弱基线,而是一个几乎零参数、却与下游任务高度对齐的强先验。再加上 fMRI 的数据规模和 BWAS 本身极小的真实效应量,让 scaling 生效的两个前提(海量数据与可学的强信号)在这里都并不充分。在这样的目标函数、这样的数据规模下,基座模型的 embedding 凭什么能学到 FC 已经显式给出的那部分个体差异结构?如果在统一、公平的下游评测里,它连这条基线都打不过,那需要被重新审视的或许不是数据,而是预训练目标本身。
这一判断,在最经典的指纹识别(fingerprinting)任务上得到了验证。各个 foundation model 同样在 HCP-YA 上训练,结果却相当炸裂,以 ROI 时间序列为输入的模型(BrainLM 家族、Brain-JEPA),没有一个能在识别率上超过传统 FC,而它们最高也只到 0.58,Brain-JEPA 甚至低到 0.07;唯一明显超过 FC 的 NeuroSTORM,本身是 voxel 级的时空模型。然而在 4 个 run 的ICC上,几乎所有 foundation model 又都反过来大幅高于 FC。这组看似矛盾的结果其实指向同一件事, embedding 可靠,却不可识别。Fingerprinting 在几万维的 FC pattern 上做最近邻匹配,靠的是高维冗余带来的近乎唯一的条形码,哪怕每条边都很噪;而 mean ICC 只逐维平均可靠性、并不奖励维度。Foundation model 把信号压成低维,每一维都很稳的表示,于是 ICC 很高,却同时把个体间那种高维、零碎的特异性抹平了,Brain-JEPA 0.88 的 ICC 配上 0.07 的识别率,就是这一取舍最极端的写照。
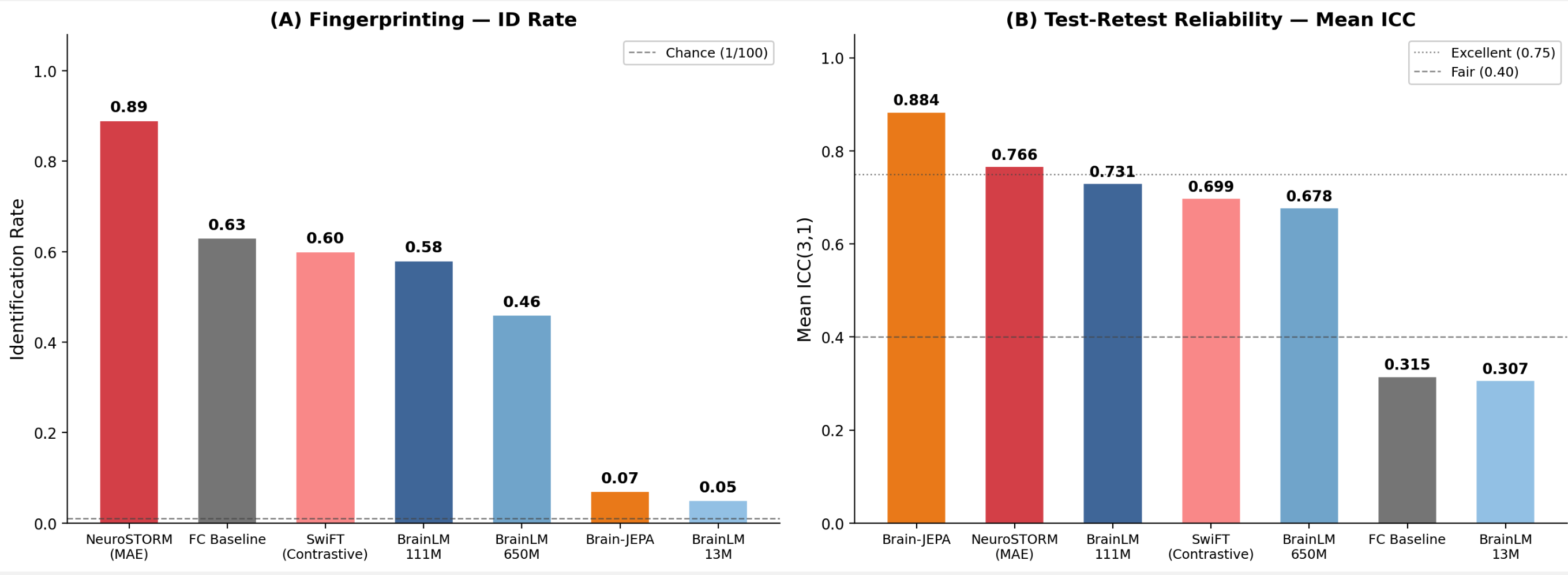
两条线索接起来,结论就清楚了:自监督学到的是稳定、共享的主导成分,偏偏丢掉了 BWAS 真正要的 trait-level 个体特异性。所以高 ICC 不等于更能刻画个体差异,可靠不代表可识别,而一个可靠却认不出人的表示,对 BWAS 其实是坏消息。